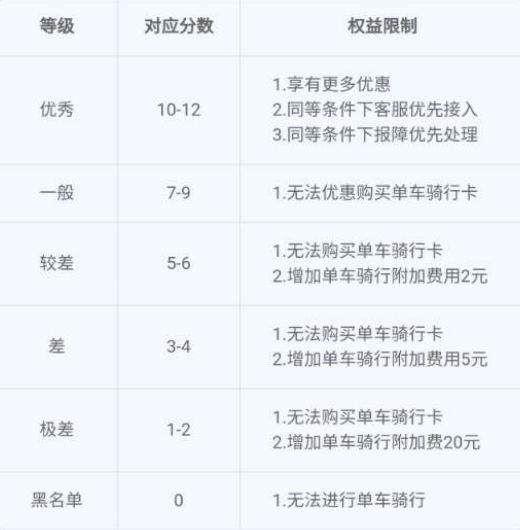
這是一張目前通行的第二代居民身份證,有國徽的這面是正面,有個人信息的是反面,底部這串 18 位的編碼是身份證號。
 (相關資料圖)
(相關資料圖)
從左到右前 6 位數是地址碼,參考行政區劃代碼,依次代表省級、市級、縣級所在地區。
不過,由于行政區劃代碼曾多次修訂,哪怕來自同一個地方,身份證上這 6 位也可能不一樣。
隨后 8 位數字是出生日期碼,接下來的 3 位是該日期出生嬰兒的順序碼,在 000 到 999 之間,偶數被分配給女性,奇數被分配給男性。
那么,最后一位代表什么?為什么有人是數字,有人是 X 呢?
前 17 位數字說盡了身份證主人的出生地、年齡和性別,而最后的字母并不攜帶實質信息,它是額外添加的校驗碼。
當我們手動輸入身份證號,除了多一位、少一位這種比較明顯的失誤,可能難以發現自己輸錯了。
而身份證最后一位的校驗碼可以快速檢測出這些錯誤,系統往往會彈出提醒,讓用戶重新輸入:
那么,校驗碼是怎么發現身份證格式錯誤的?
身份證最后一位校驗碼數值通過 MOD 運算得出,通過代入身份證前 17 位數字,計算出最后 1 位校驗碼,采用的算法是 MOD 11-2。
具體公式長這樣:
這是一個求余公式,a? 和 W? 的乘積之和除以 11,余數是 1。
i 代表身份證號從右到左的位置序號,a? 對應第 i 位置上的身份證數字,它們都為 0 到 10 之間的整數。現在以這個身份證號為例,計算一下 a 的數值。
公式中的 W? 以 2 為基數,由另一個公式求余算出。根據公式,把所有 a? 和 W? 的數值相乘,再將乘積相加除以 11,已知余數為 1,由此可以計算出此處 a 的值是 10。
也就是說,這個身份證號最后 1 位應該是 10,但直接用數字 10 會讓號碼從 18 位變成 19 位,因此用羅馬數字 X 來替代 10。
身份證號最后一位 1-X 校驗碼都由此公式算出,如果你的身份證號出現 X,說明根據前 17 位計算出的數值剛好為 10。
X 的存在解決了位數的問題,但有可能給身份證主人帶來煩惱,比如一些網站將身份證號的后 6 位作為初始密碼,卻不支持輸入字母。
既然 10 這么麻煩,為什么不干脆去掉它,把校驗碼的范圍限定在 0 到 9 呢?這是因為 MOD 11 算法識別各類錯誤的概率都在 90% 以上,MOD 10 算法則無法保證如此高的識別率。
不止身份證號里有校驗碼,日常許多編碼都會用到,但計算校驗碼的方法各異。比如,法人和其他組織統一社會信用代碼用的是 MOD 31-3 算法,需要除以 31 取余數,得到的校驗碼在 0 到 30 之間,大于等于 10 的數字用英文字母代替。
商品條碼的校驗碼算法則不涉及余數,通過加減計算得出。
我們每天都要用到的二維碼(QR Code),則用到了更為復雜的里德 - 所羅門編碼,通過它生成的碼,已經超越了普通校驗碼 " 發現錯誤 " 的層次,上升到能 " 糾正錯誤 " 的 level。
糾錯級別最高的一款,就算碼上高達 30% 的信息無法識別,依然可以還原出完整信息。
身份證號末尾的數字和 X 是與主人沒有關系的信息,但作為校驗碼中的一員,它僅有的一個字節隱藏著一連串的計算,在你輸錯時彈窗提醒,悄悄地刷一把公式的 " 存在感 "。
你認識身份證號自帶 X 的人嗎?歡迎在評論區和我們交流。
-

焦點速讀:合同引資額518億元,南陽簽約項目51個
頭條 22-11-06
-

熱推薦:從引進來到走出去,良品鋪子帶上“致富經”四次參展進博會
頭條 22-11-06
-

鄭州市新冠肺炎疫情防控指揮部辦公室關于新增新冠肺炎確診病例和無癥狀感染者涉及風險點位的通報
頭條 22-11-06
-

牧原股份:10月生豬銷售收入149.37億元
頭條 22-11-06
-

【環球新視野】商務部回應加拿大要求三家中企撤出對加礦產企業投資
頭條 22-11-06
-

洛陽市新冠肺炎疫情防控指揮部辦公室關于全市域核酸檢測結果的通告
頭條 22-11-06
-

世界觀速訊丨漯河市源匯區公布1例初篩陽性人員部分活動軌跡
頭條 22-11-06
-

焦點快報!應急管理部消防救援局副局長張福生被查
頭條 22-11-06
-

焦點關注:獲配超100億!險資追捧公募REITs,"戰投+網下"搶籌,這三家最賺
頭條 22-11-06
-

熱消息:增長17.1%!前三季度河南省企業營業總收入3.1萬億元
頭條 22-11-06
-

天天微速訊:河南昨日新增本土確診病例16例,本土無癥狀感染者174例
頭條 22-11-06
-

國家衛健委:昨日新增本土確診病例526例,新增本土無癥狀感染者3894例。
頭條 22-11-06
-

商丘鐵投擬發行20億元私募債,已獲上交所受理
頭條 22-11-06
-
全球短訊!國考報名結束:259.77萬人通過審查,錄用比約70比1
頭條 22-11-06
-

環球看熱訊:平頂山寶豐縣發布最新通知:有序恢復生產生活
頭條 22-11-06
-

快看:直擊鄭州富士康一線|工友們,醫生就在你身邊
頭條 22-11-06
-

看熱訊:甘肅多家醫院調整就醫流程 門診患者核酸結果互認
頭條 22-11-05
-

環球新動態:超780億!公募打新最新成績單
頭條 22-11-05
-
王凱在鄭州市調度指導疫情防控工作
頭條 22-11-05
-

-

世界快資訊丨速查!濟源公布3名外地來濟重點風險人員活動軌跡
頭條 22-11-05
-

視頻 | 直擊鄭州富士康一線:清潔衛士來增援了,整潔的家在歸來
頭條 22-11-05
-

世界觀速訊丨洛陽多地發布最新人事任免
頭條 22-11-05
-
焦點熱議:鄭州市水利建筑勘測設計院定向捐款100萬助力疫情防控
頭條 22-11-05
-

心系母校!河南農業大學校友捐贈過冬防疫物資
頭條 22-11-05
-

微速訊:鄭州大學校友會:守望相助,同心抗疫,感謝校友和愛心人士的捐贈
頭條 22-11-05
-

鄭州又一家公司IPO輔導備案,從事專用設備制造
頭條 22-11-05
-

環球快播:教育部設立高校疫情防控投訴平臺
頭條 22-11-05
-

焦點消息!甘肅衛健委:堅決杜絕120打不通、無車可派情況
頭條 22-11-05
-
中國人民銀行黨委委員、副行長范一飛被查
頭條 22-11-05
-

前沿資訊!立方風控鳥·早報(11月5日)
頭條 22-11-05
-

全球今日訊!河南昨日新增本土無癥狀感染者131例
頭條 22-11-05
-

天天熱點!美國民調:大多數人稱高通脹“都賴拜登”
頭條 22-11-05
-

國家衛健委:昨日新增本土確診病例596例,新增本土無癥狀感染者3063例
頭條 22-11-05
-

人民幣強勁反彈!兌美元在岸離岸均漲超1200點!專家:仍將維持雙向波動走勢
頭條 22-11-05
-

環球觀點: 隔夜歐美·11月5日
頭條 22-11-05
-

訊息:濟源示范區新冠肺炎疫情防控指揮部辦公室公告
頭條 22-11-05
-

當前熱議!鄭州全力確保今年新建高標準農田4.57萬畝
頭條 22-11-05
-

當前通訊!鄭州管城回族區新冠肺炎疫情防控指揮部辦公室關于調整部分區域疫情防控措施的通告
頭條 22-11-04
-
楊德龍:消費、新能源和科技龍頭股聯袂上攻 大盤成功收復三千點!
頭條 22-11-04
-

天天快報!應對疫情影響,開封出臺服務企業安全生產十條措施
頭條 22-11-04
-

天天快看:立方風控鳥·晚報(11月4日)
頭條 22-11-04
-

當前聚焦:上期所與金川集團簽訂戰略合作協議,共推多層次大宗商品交易市場體系建設
頭條 22-11-04
-
環球觀天下!豫論場|向前趕,向前看
頭條 22-11-04
-

每日短訊:龍佰集團終止籌劃在港交所上市
頭條 22-11-04
-

天天新資訊:每天休息4小時 他們保供幾百戶的新鮮菜丨鄭歸來?面孔
頭條 22-11-04
-
獨居老人的特殊“陪診員”丨鄭歸來·面孔
頭條 22-11-04
-

速讀:中央網信辦:強化網暴當事人保護,網站平臺要提供一鍵關閉陌生人私信等設置
頭條 22-11-04
-
動態焦點:封閉管理保生產,鄭州經開區企業多舉措應對疫情|鄭歸來·現場
頭條 22-11-04
-
當前滾動:風控加碼,多家銀行調整信用卡持卡量,信用卡業務下一步如何做?
頭條 22-11-04
-

快資訊丨北京證券交易所發布北證50成份指數樣本
頭條 22-11-04
-

天天短訊!一根不起眼的搭電線丨鄭歸來·面孔
頭條 22-11-04
-
千味央廚:供應鏈穩定運行,可有效確保鄭州市場供應丨鄭歸來·現場
頭條 22-11-04
-

外賣小哥戰“疫”感言:最大動力源自市民理解丨鄭歸來·面孔
頭條 22-11-04
-

世界百事通!超20城推二手房“帶押過戶” 激發市場活力
頭條 22-11-04






































































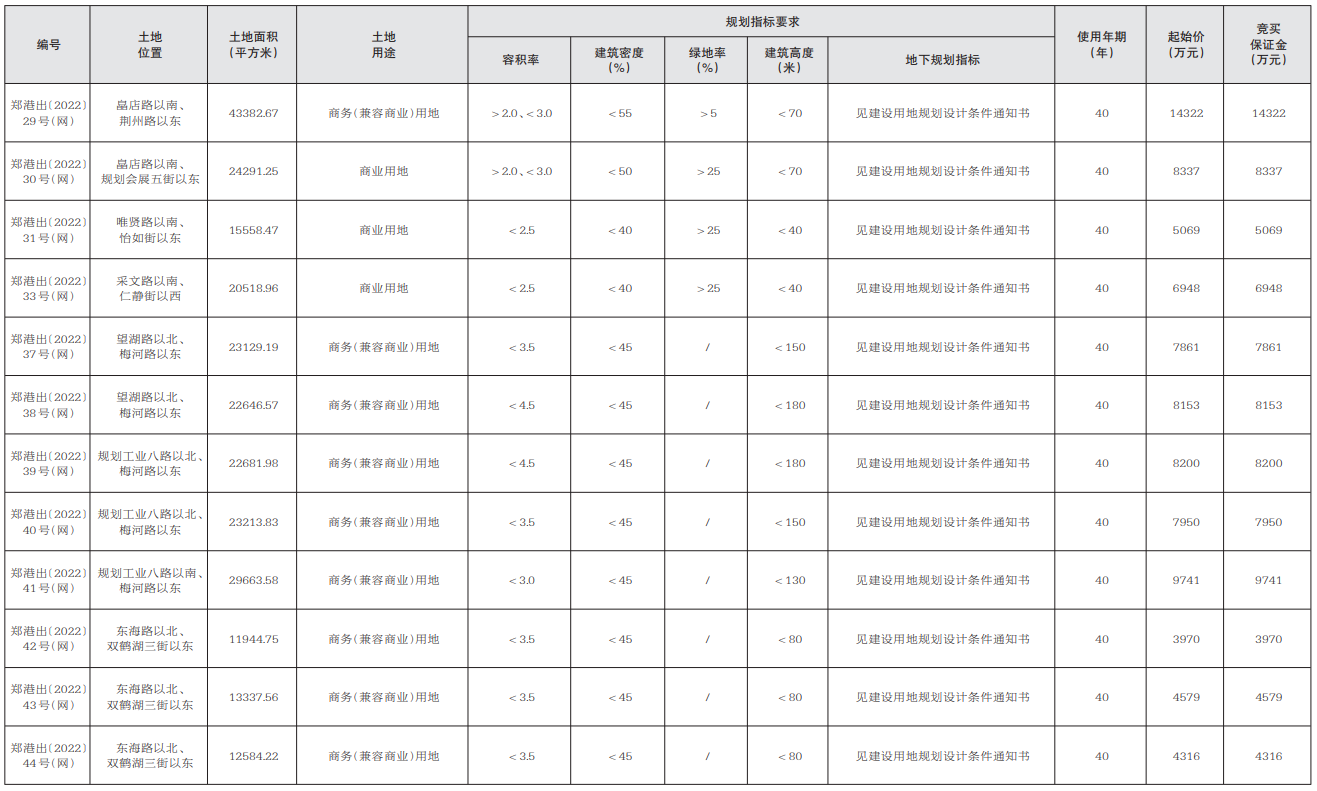



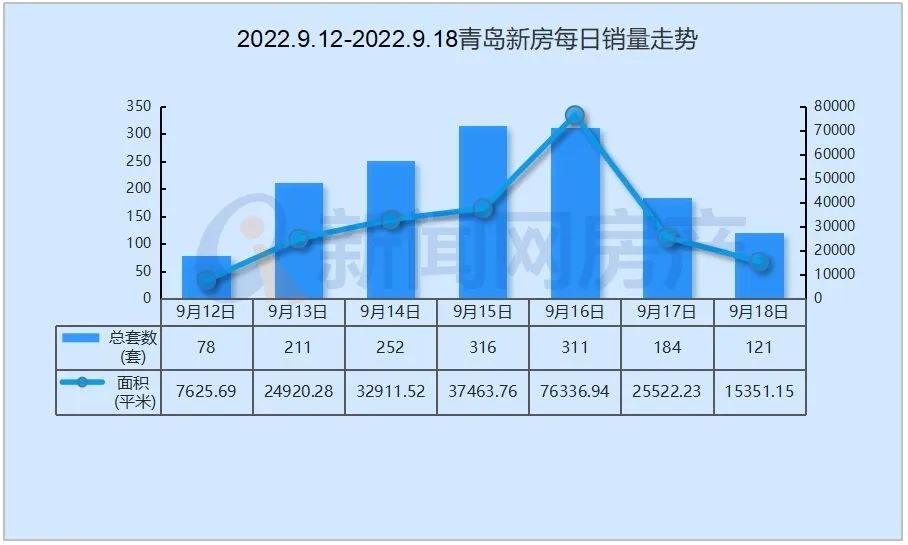

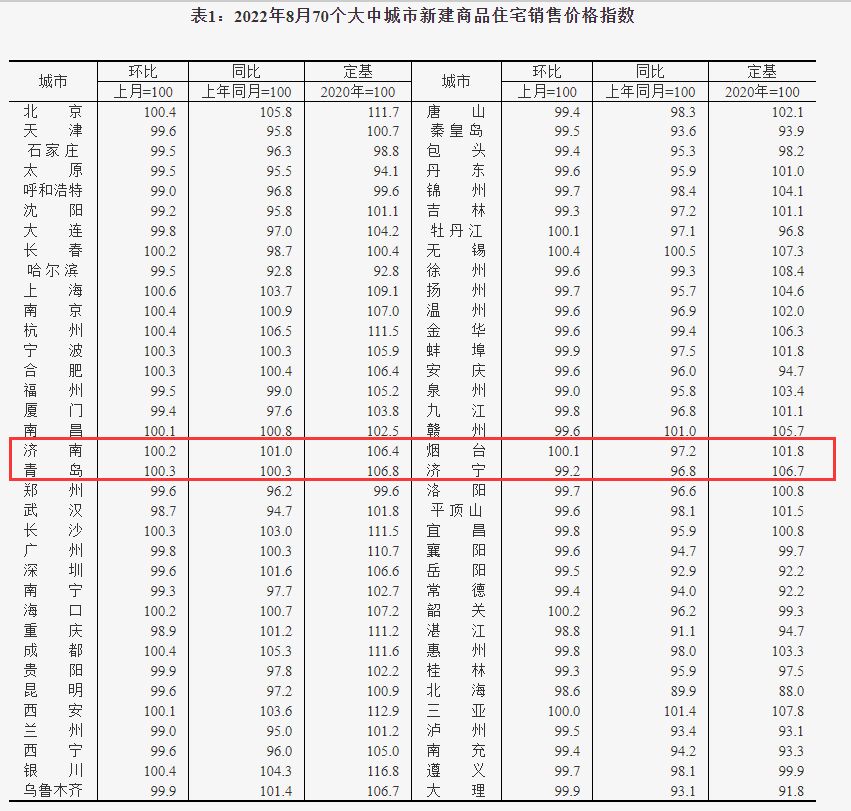
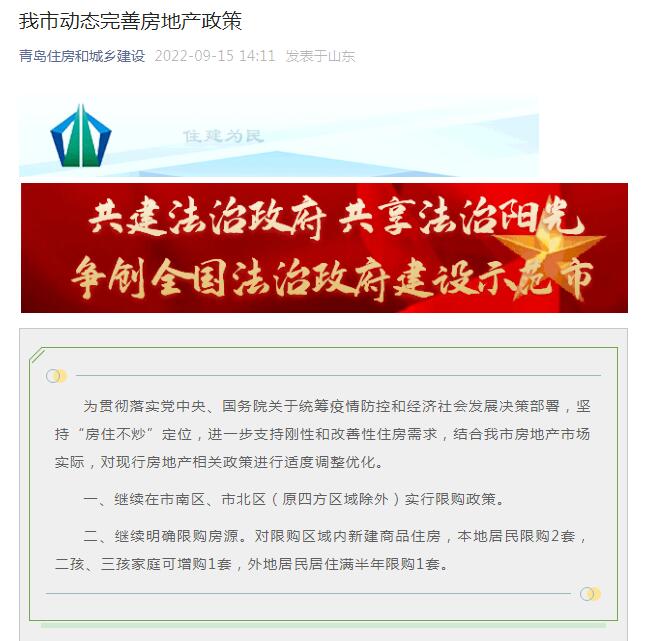














































- 環球聚焦:身份證尾號是 X 的人到底有多2022-11-06
- 全球快消息!阿奴拜克 · 庫彎、夏雨雨分2022-11-06
- 世界今熱點:二里頭遺址:打開神秘夏朝的文2022-11-06
- RCEP遇見進博會帶來雙重積極效應 促全球經2022-11-06
- 【環球新視野】候鳥遷徙過境江蘇 好生態引2022-11-06
- 世界熱頭條丨英媒:抨擊中國不會給歐洲帶來2022-11-06
- 全球視點!中學里開了一家“樹洞”郵局2022-11-06
- 焦點速讀:合同引資額518億元,南陽簽約項2022-11-06
- 環球熱資訊!有擔當!黨員志愿者堅守富士康2022-11-06
- 天天動態:居家買藥不用愁! “藥品配送直2022-11-06
- 大瓜!日本頂流聲優被爆隱婚出軌 10 年,2022-11-06
- 力壓韓國隊!短道速滑混合接力,中國隊奪冠2022-11-06
- 山東東平縣發生一起爆炸:致 1 死 1 重2022-11-06
- 今頭條!北京電視秋交會舉行微短劇論壇:短2022-11-06
- 預制菜亮相進博會2022-11-06
- 熱推薦:從引進來到走出去,良品鋪子帶上“2022-11-06
- 鄭州市新冠肺炎疫情防控指揮部辦公室關于新2022-11-06
- 牧原股份:10月生豬銷售收入149.37億元2022-11-06
- 天天熱推薦:當戲曲邂逅“四大名著”與古典2022-11-06
- 當前聚焦:從大白、小藍到紅馬甲,他們筑起2022-11-06
- 世界通訊!《個人養老金實施辦法》發布!怎2022-11-06
- 每日關注!靠給娃娃整容月入 4 萬!有人檔2022-11-06
- “耍這個之后腦袋里都是它”,賭客輸 1402022-11-06
- 當前快報:DRX 奪得英雄聯盟 S12 全球總2022-11-06
- 韋筱圓高低杠衛冕, 鄒敬園吊環摘銀2022-11-06
- 一起見證中國的開放之諾2022-11-06
- 全球看點:新疆:“三山兩盆”孕育濕地之美2022-11-06
- 廣州海珠區新增1253名感染者,個別市民擅自2022-11-06
- 韓國男團在印尼演出發生歌迷推擠,致30人暈2022-11-06
- 00后大二女生休學與妹妹賣畫救白血病母親:2022-11-06










